
The Tech Stack for AI-Native Go-to-Market
What infrastructure does an AI-native go-to-market organization need?

How do you build a tech stack that leverages the capabilities of modern-day AI to grant superpowers to your GTM team? That’s what we are looking at today.
In my last article, I described how an AI-native GTM organization operates: signal-based, in cross-functional pods, with clearly defined roles instead of rigid job descriptions. What I deliberately left out, for the most part, was the question of tools and technological infrastructure.
For a reason. Because this is exactly where one of the most common mistakes happens in practice: too many GTM teams start with the tools. They evaluate software, run pilots, build a stack - and only then ask how the work should actually be organized. The result: a historically grown patchwork of point solutions that neither talk to each other nor fit the actual workflows.
In other words, the cart is often put before the horse. Because the real starting point should be:
How do we want to work with AI and agents going forward? What tasks can they take over and what new workflows do they enable? And what infrastructure do we need for that?
The difference in approach isn’t trivial. It changes the entire tool selection process. Instead of asking “What’s the best CRM?” the question suddenly becomes: “What data needs to flow for an agent to be operational? What systems need to be integrated for a workflow to function end-to-end?”
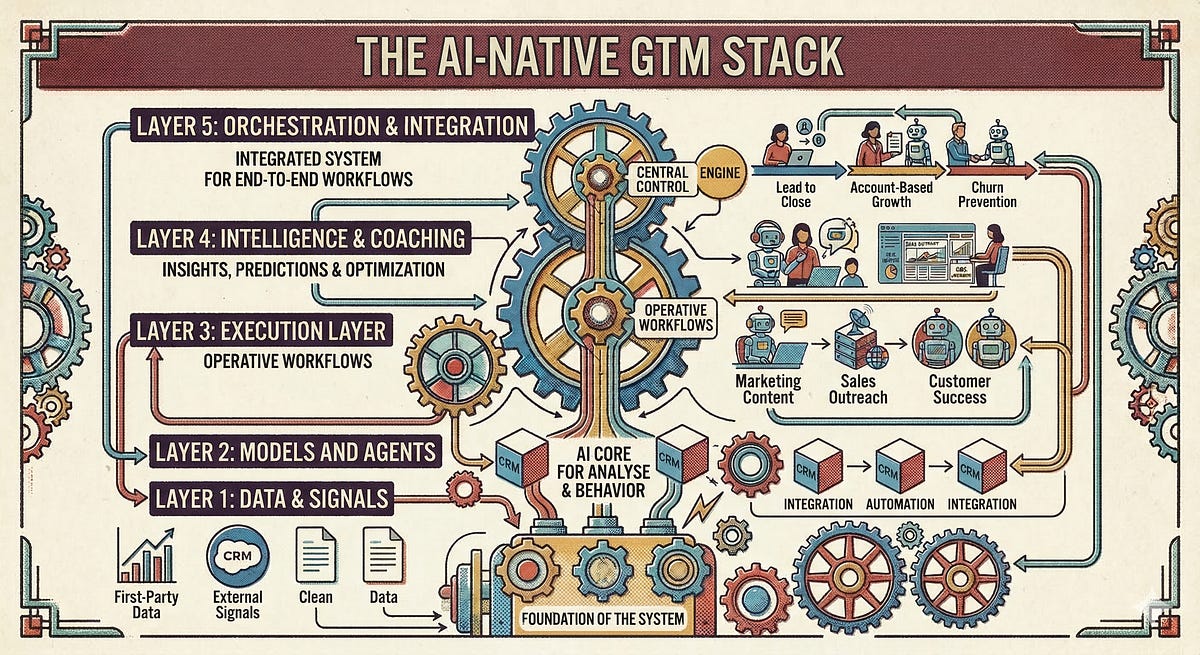
In this article, I will take a holistic look at the AI-native GTM stack. I divide the stack into five layers, explain the “jobs to be done” at each level, and to keep things from getting too theoretical, I also name a selection of tools for each layer - mostly European solutions that take GDPR compliance seriously by design.
That said: countless AI-first GTM tools are currently sprouting up everywhere. Some are specialist tools for narrowly defined tasks, others are integrated solutions that cover aspects across several of the layers I describe in here. The implication for you: when building your own GTM stack, you obviously don’t need to purchase a separate tool for every layer. Many solutions can cover multiple requirements.
Layer 1: Data & Signals - The Foundation Everything is Build on
All AI-based workflows are only as good as the data they operate on. That sounds like a truism - and yet it’s systematically underestimated. In many GTM teams, the CRM is a data graveyard: incompletely maintained, poorly integrated, not enriched with external signals.
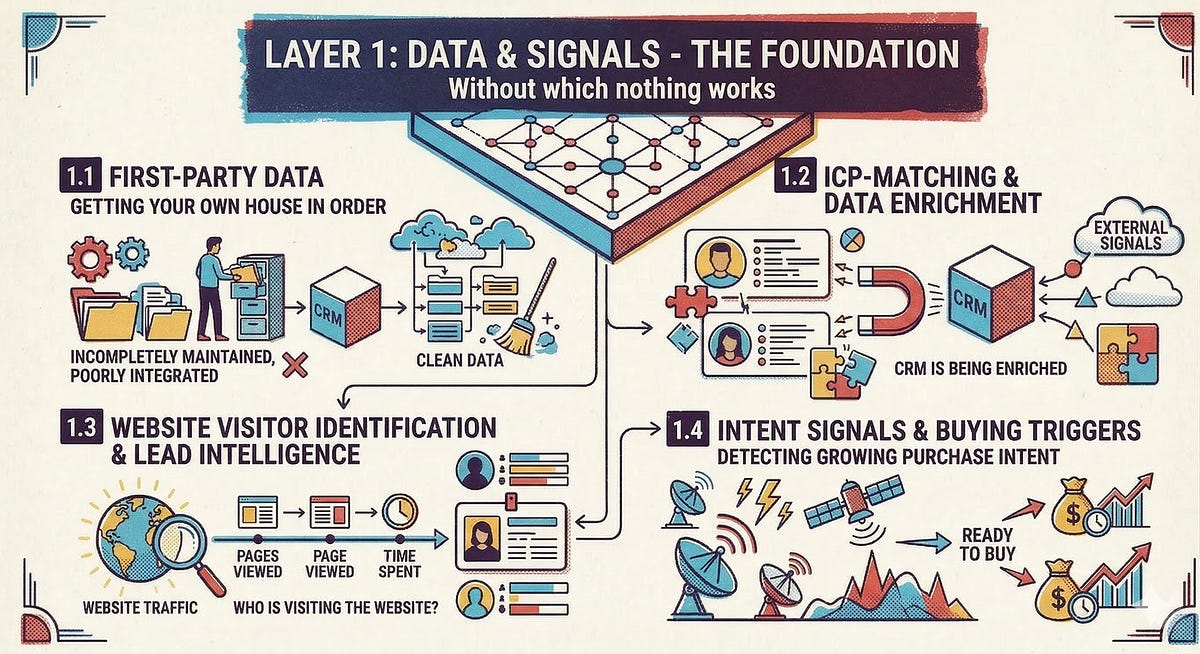
1.1 First-Party Data: Getting Your Own House in Order
Before we discuss data enrichment and intent signals, we shall look at the often-neglected foundation: your own data. Customer data in the CRM, product usage data, support tickets, marketing engagement metrics, contract information from the billing system - all of this is valuable first-party data. Alas, it’s scattered across half a dozen systems all too often. As long as this data exists in silos, no agent and no ML model can unlock its full potential.
The architectural answer is the Data Lakehouse - a concept you can think of as a central data store that combines the flexibility of a data lake with the structure and queryability of a traditional data warehouse. In practical terms, this means: CRM data, product usage data, and marketing metrics end up in one place that both BI tools and AI models can access - without data needing to be painstakingly transformed and copied for every use case. Vendors like Databricks or Snowflake have brought this architecture to market maturity in recent years. If you want to go deeper, Google has an accessible explanation of the concept.
Another architectural concept that fits particularly well with our pod-based organizational model - and becomes increasingly interesting the as the GTM organization scales and matures - is the Data Mesh. The core idea: instead of having all data managed centrally by a data engineering team, the respective funtional teams take ownership of their own datasets and make them available for the organization in the shape of clearly defined “data products”. This model, developed and described by Zhamak Dehghani, mirrors the decentralized responsibility logic we’ve already established in the organizational design on the data level.
The implication for CROs? Anyone who wants to seriously scale their AI workflows has to treat their own data architecture as a strategic priority.
1.2 ICP Matching and Data Enrichment
Who are the right accounts and contacts - and how do we automatically enrich our master data with current company information, firmographics, and contact details? Cognism has established itself as the European gold standard here: GDPR-native, with phone-verified mobile numbers and a strong focus on European markets.
1.3 Website Visitor Identification and Lead Intelligence
Which companies are visiting our website - and how do we qualify these signals automatically? Solutions like Salesviewer, Leadfeeder, or ipstack are options that perform IP reverse lookup and combine it with data enrichment.
1.4 Intent Signals and Buying Triggers
Which accounts are currently showing active buying interest - beyond our own website? Providers like Dealfront or Open Prospect deliver intent data and account insights as EU-native solutions.
The key takeaway: Without a clean, integrated data layer, agents are blind. They may produce output - but not relevant output. This layer is the most underestimated investment in the entire stack.
Layer 2: Models and Agents - aka the AI Generalists
Before we get to specialized tools, no GTM stack today can do without LLMs and other generalists from the AI world.
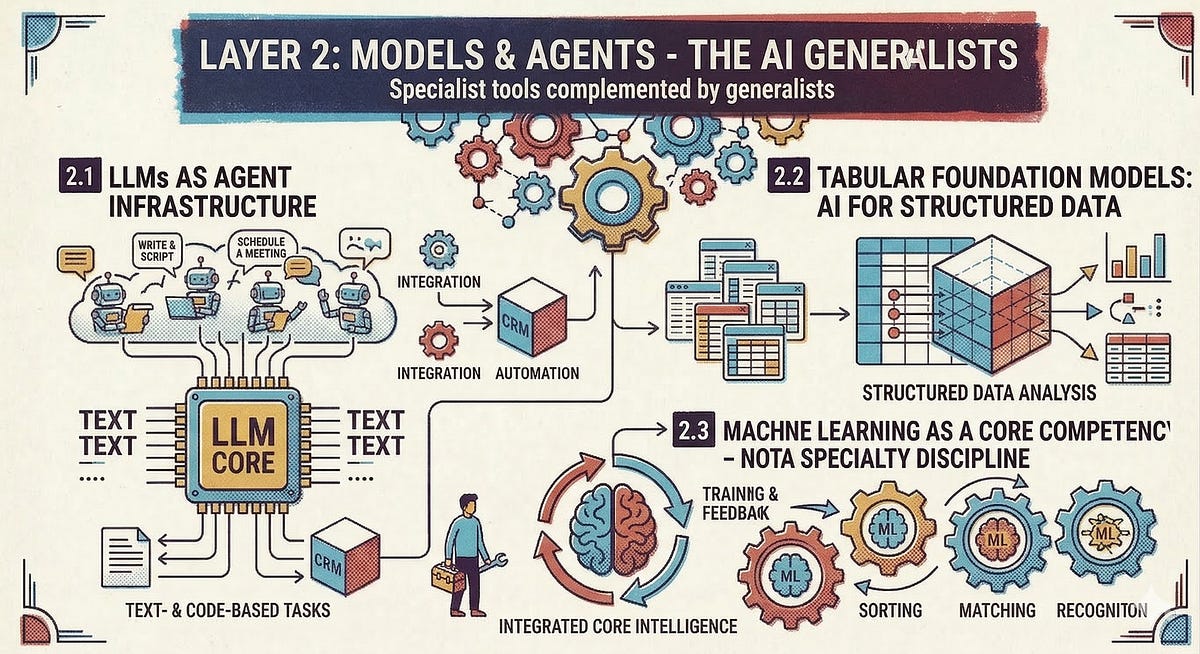
2.1 LLMs as Agent Infrastructure
Every agent that writes emails, qualifies signals, or summarizes research needs access to a capable large language model. Anthropic’s Claude has established itself as one of the strongest models for complex GTM tasks - from research to content creation to analytical workflows. For European companies, GDPR compliance is non-negotiable here. Specialized providers like Langdock or Neuland.ai make Claude and other models available in a privacy-compliant environment.
A development that is massively accelerating this model right now is the Model Context Protocol (MCP), an open standard that defines how LLMs and agents can access external tools and data sources in a structured way. In practical terms, it works like this: more and more tools - from CRMs to communication platforms to databases - provide so-called MCP servers through which an agent can not only read data but also execute actions: update a deal in the CRM, start a sequence, prepare a deck, create a meeting.
Consequently, it’s becoming increasingly realistic for GTM teams to make their LLM the central interface of their daily work, while the surrounding tools like HubSpot, Slack, or the calendar become services orchestrated by agents. We may not be completely there yet, but the infrastructure is emerging at a breakneck pace right now. In other words:
Anyone evaluating their GTM stack today should have MCP compatibility as a key selection criterion.
But - and this is a crucial point - an LLM alone does not make an AI-native GTM team. LLMs are excellent at understanding and generating language: drafting emails, producing and summarizing research, creating meeting notes. They are not built to analyze structured datasets, detect statistical patterns in tabular data, or deliver reliable predictions based on historical metrics.
2.2 Tabular Foundation Models: AI for Structured Data
A large portion of operational GTM data is tabular: CRM records, pipeline data, usage metrics, engagement scores. For this type of data, there is a distinct class of AI models that is maturing rapidly: Tabular Foundation Models (which Peter Milan Trapp brought to my attention a few months ago and demonstrated their potential through compelling use cases 🙏).
The principle: similar to how an LLM was trained on vast amounts of text and thereby “understands” language, Tabular Foundation Models are trained on large volumes of tabular data. This enables them to make surprisingly useful predictions even with relatively small datasets, without requiring you to train a model from scratch.
Prior Labs’ TabPFN is one such model. It can perform classifications and predictions on the basis of typical GTM datasets - say, a CRM export with a few thousand data points - that compete with elaborately trained machine learning models. For GTM teams, this opens up concrete use cases: churn prediction based on usage signals, lead scoring from historical conversion data, or identifying upsell patterns in account data. And all of this without having to build an entire data science team.
2.3 Machine Learning as a Core Competency - Not a Specialist Discipline
Nevertheless, it’s worthwhile for GTM teams to know the machine learning toolbox well. Many of the analytical challenges that arise in day-to-day operations can be solved with proven ML methods - often more simply, cheaply, and robustly than with generative AI.
Two examples: Lead Scoring - prioritizing incoming leads by close probability - is a classic classification problem. Current research shows that ML-based scoring models trained on historical CRM data significantly outperform rule-based scoring systems.
Pipeline Forecasting is another example: instead of relying on the subjective assessment of individual reps (“That deal is closing this month”), ML models can analyze historical deal trajectories, engagement metrics, and activity data to deliver significantly more precise forecasts. Some RevOps teams report forecast accuracies above 90 percent - a level no purely human process achieves.
The implication for CROs: Machine learning is a core competency. Of course, not every GTM team needs an ML expert in-house; smaller organizations can also bring in external specialists. I can warmly recommend Laurenz Wuttke and his team.
In summary: An AI-native GTM stack doesn’t need one AI tool - it needs at least three types: LLMs for language-based tasks, Tabular Foundation Models for structured data analysis, and classical ML methods for more complex tasks like scoring and pattern recognition. Anyone relying solely on LLMs is leaving a significant portion of the potential on the table.
Layer 3: Execution Layer - The Operational GTM Work
This is the layer where most of the actual GTM work happens. The job of solutions on this layer is to execute marketing, sales, and CS tasks and workflows.
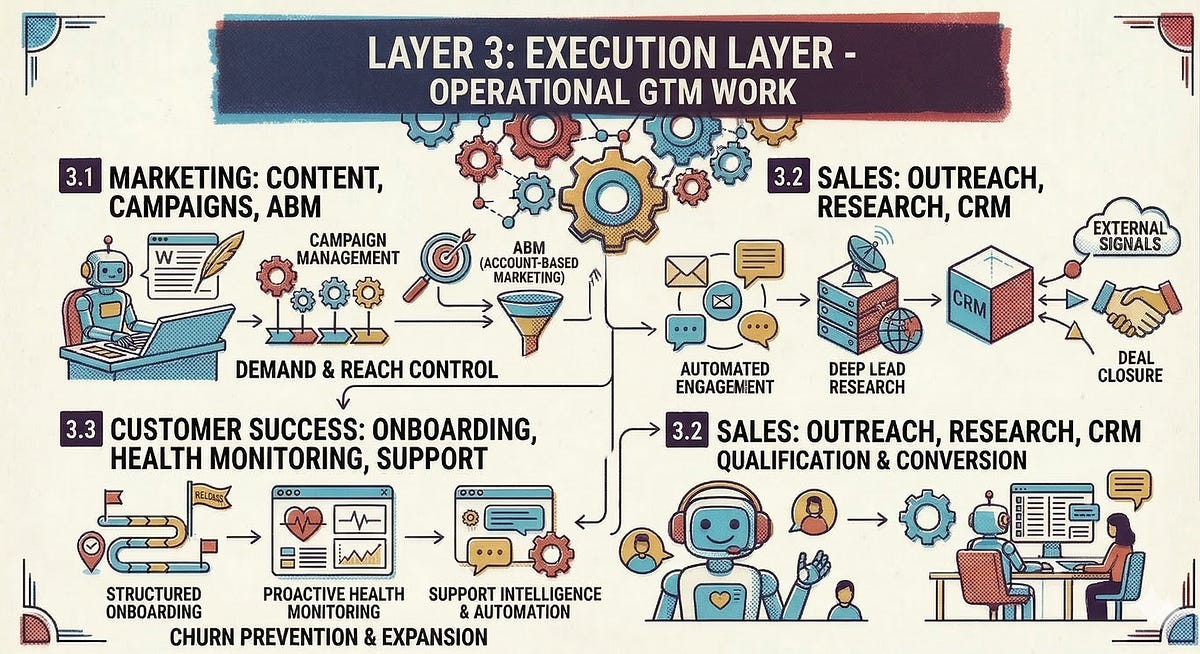
3.1 Marketing: Content, Campaigns, ABM
In the first article, I described how AI takes over high-volume content production (with human-in-the-loop quality assurance), personalizes campaigns, and automatically launches and monitors ABM campaigns. Technologically, this requires three things: generative AI for content creation, marketing automation with AI support, and intelligent campaign orchestration.
HubSpot Marketing Hub and the Adobe Experience Cloud have positioned themselves as integrated solutions that combine content creation, management, and campaign automation in a single platform.
3.2 Sales: Outreach, Research, CRM
AI handles CRM documentation, signal-based outreach sequences, and pre-call research. This requires a sales engagement tool that natively supports agent workflows and a CRM that serves as the system of record.
Examples of AI-native sales engagement platforms that integrate signal-based outreach, research, and sequencing (while handling data in a GDPR-compliant manner) include Everlead and Amplemarket. As a CRM, HubSpot or Salesforce remain the natural anchor - though the actual intelligence increasingly resides not in the CRM itself, but in the agents that access it.
For deep research and the contextualization of complex accounts, Clay provides a powerful workflow layer: it aggregates data from dozens of sources, enriches it, and makes it usable for agents. Clay simultaneously serves as both a research and orchestration tool.
3.3 Customer Success: Onboarding, Health Monitoring, Support
In CS, AI automates onboarding workflows, first-level support, churn risk scoring, and health score monitoring, among other things. Technologically, this requires a CS platform and an AI-powered support layer.
Vitally offers a CS platform that covers health scores, automated playbooks, onboarding tracking, and escalation triggers. For first-level support, Intercom has established its AI agent Fin as a strong solution - an agent that handles FAQ inquiries and only escalates to humans when complexity demands it. Both solutions offer GDPR-compliant deployment options.
Layer 4: Intelligence & Coaching - Supporting Human Judgment Through Technology
When AI takes over the (initial) execution of many workflows, the focus for us humans shifts increasingly toward exercising judgment, relationship building, and prioritization. There is, of course, technological support for this as well.
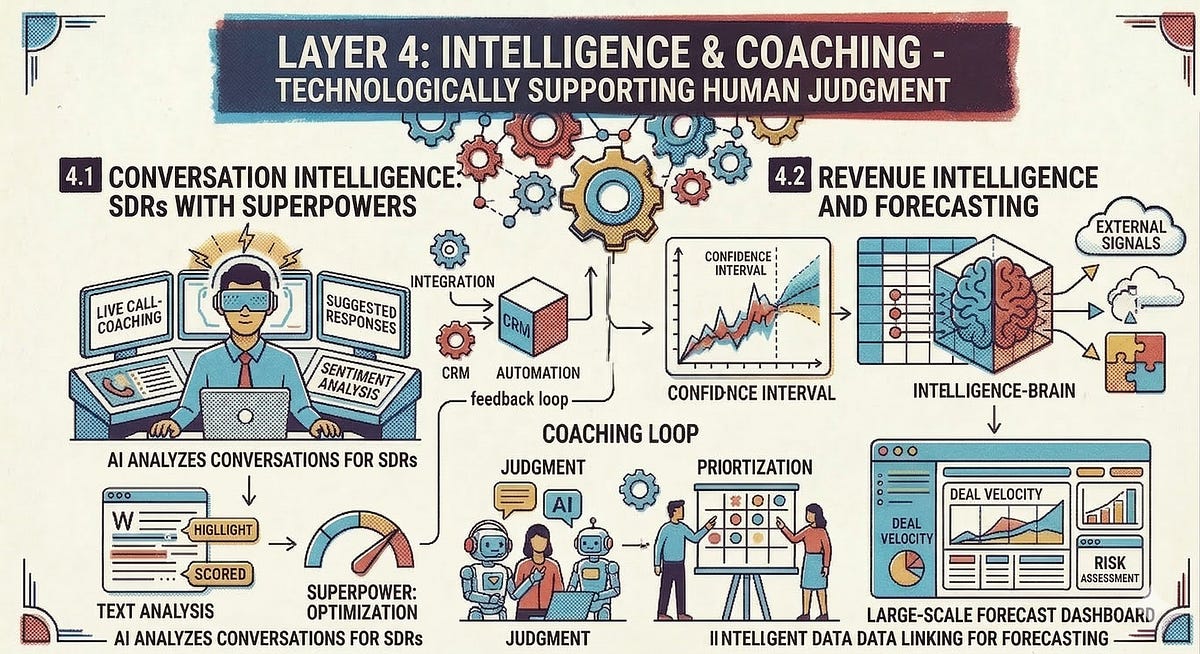
4.1 Conversation Intelligence: SDRs With Superpowers
True conversation intelligence is more than a mere recording tool. Rather, it enables systemic pattern recognition across hundreds of conversations. Which objections come up repeatedly? Which conversation patterns correlate with successful closes? Where do reps need coaching? AI can also help with call preparation through reports and briefings, equipping SDRs with AI-generated battle cards that are tailored to specific customers.
Gong is the market leader here. For teams looking for an EU-native alternative, Modjo and Everlead are good options - developed in Europe, GDPR-native by design, and equipped with comparable functionality for conversation analysis and coaching insights.
4.2 Revenue Intelligence and Forecasting
How healthy is the pipeline really - beyond what’s been logged in the CRM? Revenue intelligence has the task of providing revenue teams with insights and enabling more precise forecasts. This includes use cases from AI-powered forecast modeling to pipeline analysis. Clari’s “Revenue Platform,” for example, addresses exactly this.
Layer 5: Orchestration & Integration - From Tools to System
An AI-native GTM stack is not a product catalog. It’s a system. And the decisive question is which workflows should ultimately be mapped. Regardless of which individual tools are ultimately deployed, there will typically be quite a few.
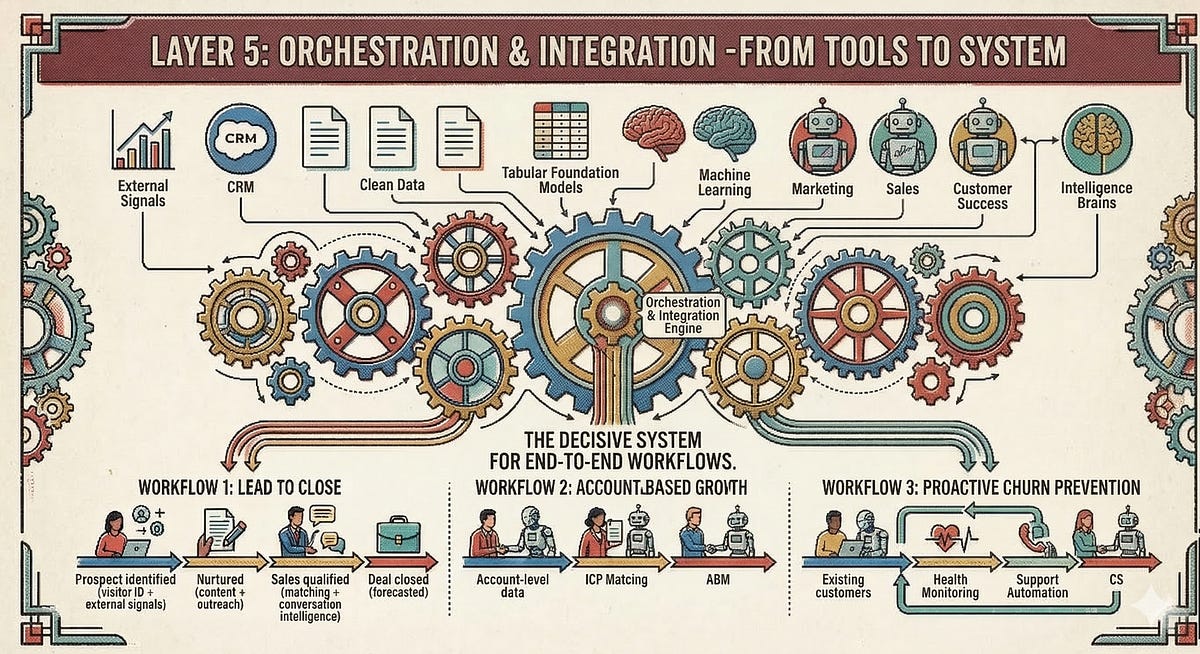
This is where the roles of the GTM Engineer and AI Workflow Architect from the operating system for AI-native GTM organizations come into play: someone needs to build, maintain, and optimize the connections between tools across the different layers. This is not a one-time implementation but an ongoing responsibility.
Technologically, this requires workflow automation and data orchestration. There are platforms for this too. n8n has proven particularly well-suited for AI-native GTM contexts: whether as a SaaS solution or self-hosted (#GDPR), with native support for LLM integrations and complex, multi-step agent workflows. Make offers related functionality with a lower entry barrier and a German hosting option. Clay can also be mentioned again in the orchestration layer, as it can cover several scenarios with its numerous integrations and “Claygents.”
From Stack to Implementation
The Stack at a Glance
The following overview shows all layers of the AI-native GTM stack at a glance.
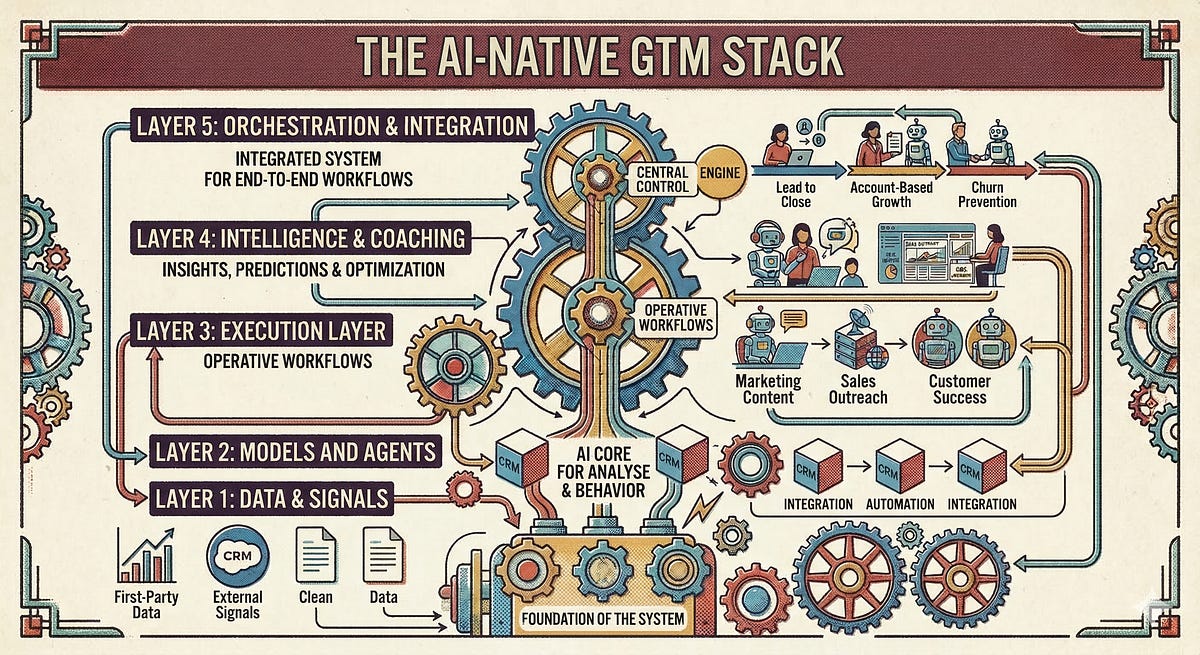
The question that naturally arises is: how do you build your own stack and which solutions do you choose? That decision depends on various factors - from your existing systems and their compatibility with other solutions to your team’s affinity for technology. A final selection can therefore only be made sensibly on a case-by-case basis. Still, I want to leave you with two closing thoughts on the subject.
Custom Setup vs. Integrated Solution
When it comes to building your AI-native GTM stack, you have to decide whether you want to use various specialized solutions and stitch them together precisely tailored to your needs or whether you procure an integrated solution that has most capabilities and makes them easy to use.
There are pros and cons for both paths. If you have a technically proficient team, sensibly combined point solutions across all stack layers can often hit the target more precisely while saving on software costs. Additionally, in today’s dynamic AI environment, this approach makes it easier to quickly leverage and evaluate new possibilities.
But the complexity is significantly higher compared to platform solutions that offer tools across the entire stack and make them accessible in a user-friendly way. For those who value integration and well-designed workflows, platforms like Everlead or Amplemarket offer solutions that provide the full throughput from the data layer to orchestration.
Beyond the solutions mentioned above, there are of course many more tools. A good overview of state-of-the-art solutions can be found at Brendan Short’s ProspectingStack.com.
Build vs. Buy
In the AI era, not everything needs to be solved with existing tools. GTM Engineers will increasingly use code-generating AIs like Claude Code to build tooling for their own micro-workflows. The ability to develop such workflows internally is becoming a genuine competitive advantage.
Infrastructure Is a Design Decision
An AI-native GTM stack is not a shopping list. It’s a design decision - just like the organizational structure it supports. The question is not “Do we have enough tools?” but rather:
Is our infrastructure built so that we can achieve our GTM goals as efficiently as possible - and react quickly to changes in GTM tech?
How does your GTM stack look today - and where do you see the biggest gaps?